昨天我們看了SparkingStreamingContext的起手式與一個stateless的use case。基本上,我認為stateless不用處理關注其他的批次的關聯,就很很像一般RDD的寫法,反正就是處理批次內的資料就對了。而stateful的寫法就稍有不同了,但是stateful有許多實用的場景,最常見的就是想持續監控或統計某些欄位時,我們延續昨天的股票交易紀錄,假如我們想要:
持續監控交易量最高的客戶前5名(每N秒更新)
分析一下這樣的需求,肯定不能只處理這個批次的資料了吧,一定要知道過往的資料如何吧,那就是Stateful Streaming的範疇啦。Stateful Streaming可以再細分成兩類:
WindowDuration/Sliding duration的概念,但我們肯定不能只關注前N批吧,這種應用之後再講。維護某些值狀態,這些狀態是會一直維護狀態的,不論經過幾個批次(除非你刻意讓他停止或timeout),要實現這種維護狀態的實際API,在1.6版後有兩種API:
先看看updateStateByKey怎麼用吧,懂了之後要換到mapWithState也很簡單。
從updateSateByKey的名稱,有沒有看出他適用哪類的RDD阿??沒錯~就是pair類RDD啦,才有key阿XDD,所以在使用之前,要先把DStream RDD轉成pairDStream
昨天我們花了很多時間建出了orders,我們今天重複使用他當作資料來源,既然要知道金額最高的前5個客戶,那就在生個有金額跟客戶資訊的KV吧:
val amountPerClient = orders.map(record => (record.clientId, record.amount * record.price))
OK,我們把客戶ID當作key,每筆order的總金額當作value,再來要如何用updateSateByKey勒?,看看原始碼先:
def updateStateByKey[S: ClassTag](updateFunc: (Seq[V], Option[S]) =>
Option[S]): DStream[(K, S)] = ssc.withScope {
updateStateByKey(updateFunc, defaultPartitioner())
}
透過原始碼可以發現,要使用updateStateByKey函式最重要就是傳給它一個函式,那個函式必須包含:
Seq[V]:此值代表這批資料中,這個key相關的events,因為可能是多個,所以傳入一個Seq類別物件,Seq有點類似Java中的Collection抽象集合類別。Option[S]:代表先前此key對應到的狀態(值),當然如果此Key是第一次遇到,當然先前的狀態就會是空的麻~所以這邊用Option包起來,代表有可能為nullOption[S]:通常是回傳更新後的狀態出去,怎麼更新就是函式要做的事啦[Snippet.41]建立updateSateByKey所需更新狀態函式
來寫這個好玩的函式吧:
def func(
vals: Seq[(Double)],preValue: Option[Double]): Option[Double] = ①
preValue match { ②
case Some(total) => Some(vals.sum + total) ③
case None => Some(vals.sum) ④
}
①先確認一下我們V的類型為何?沒錯,依之前的amountPerClient,V為Double,所以我們會吃一個名稱為vals的資料,代表本批次此key值的集合,而此key之前的狀態值已經更新為的回傳值勒?應該也是Double沒錯吧~
②對狀態變數作pattern match(可以當作強化版的switch),這也是Scala處理Option物件常用的作法之一,可以仔細瞧瞧喔
③如果Option有值,會得到Some(total),Some跟Option都是Option的子類別,信不信XD:
final case class Some[+A](x: A) extends Option[A] {
def isEmpty = false
def get = x
}
沒騙你吧~extends Option,提供兩個方法,回傳不為空的isEmpty跟取值get,等等就會用到了。回到原題,如果有值(且順便被存於total變數中),當然就疊加並回傳囉:Some(vals.sum + total),vals.sum直接可以取得這批數字類RDD的加總,好用吧~
④如果沒值(None),也就是這是新Key,那就乖乖的回傳這批的加總吧Some(vals.sum)
OK,寫好函式,整入updateStateByKey吧:
val amountState = amountPerClient.updateStateByKey(func)
Spark要求用這類維護State的RDD都必須寫入checkpoint,否則中斷要從哪裡重建阿!!RDD值都是一百年前的累積下來的,DAG血統圖爆炸長,不用checkpoint截斷不行(還記得嗎checkpoint嗎):
ssc.sparkContext.setCheckpointDir("/home/joechh/chpoint")
示範是放在本機上,但一般來說都是放在HDFS或S3這類分散式+redundant儲存系統中,否則本機直接掛掉,checkpoint一起不見不就搞笑...
如果要把updateStateByKey所需函式寫成匿名函式怎麼寫?也差不多:
amountPerClient.updateStateByKey(
(vals: Seq[(Double)], preValue: Option[Double]) =>
{
Some(vals.sum + preValue.getOrElse[Double](0))
}
)
有帥一點嗎,這邊用了個偷吃步的方式簡化patten match:getOrElse,自己體會看看吧~
好,我們現在有個amountState的pairDStream,該如何一直印出前5名勒?(K是ClientID,V是總金額),如果有sortBy可以用就好了,但是pairDStream查了一下沒得用,那怎麼辦勒?如果能把他轉成一般RDD就好了,可以嗎,當然可以囉,這就是公認的Streaming後門萬用函式XD:transform,可以做RDDtoRDD轉換:
amountState.transform(_.sortBy(_._2, false))
好我可以排序了,但是怎麼抓前5名勒?沒有欄位是1到5阿...那就加個欄位,過濾後再清掉囉:
val top5clients = amountState.
transform(_.sortBy(_._2, false).
zipWithIndex. ①
filter(_._2 < 5)). ②
map(x=>x._1) ③
①加個欄位
②過濾後
③清掉
用fluent style寫functional programming真的超爽的阿~~一直串串串。但Debug時候會不太爽QQ
完整Code(10秒版本):
package SparkIronMan
/**
* Created by joechh on 2016/12/6.
*/
import java.sql.Timestamp
import java.text.SimpleDateFormat
import org.apache.spark._
import org.apache.spark.streaming._
object Day21_TopFiveCustomer extends App {
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(10))
val fileStream = ssc.textFileStream("hdfs://localhost:9000/user/joechh/sparkDir")
val orders = fileStream.flatMap(line => {
val dateFormat = new SimpleDateFormat("yyyy-MM-dd hh:mm:ss")
val words = line.split(",")
try {
assert(words(6) == "B" || words(6) == "S")
List(Order(new Timestamp(dateFormat.parse(words(0)).getTime),
words(1).toLong,
words(2).toLong,
words(3),
words(4).toInt,
words(5).toDouble,
words(6) == "B"
))
}
catch {
case e: Throwable => println("wrong line format(" + e + "):" + line)
List()
}
})
val amountPerClient = orders.map(record => (record.clientId, record.amount * record.price))
def func(vals: Seq[(Double)], preValue: Option[Double]): Option[Double] = preValue match {
case Some(total) => Some(vals.sum + total)
case None => Some(vals.sum)
}
val amountState = amountPerClient.updateStateByKey(func)
ssc.sparkContext.setCheckpointDir("/home/joechh/chpoint")
val top5clients = amountState.
transform(_.sortBy(_._2, false).zipWithIndex.filter(_._2 < 5)).map(x=>x._1)
top5clients.print()
ssc.start()
ssc.awaitTermination()
}
套用前一天的方式傳資料,看看輸出結果:
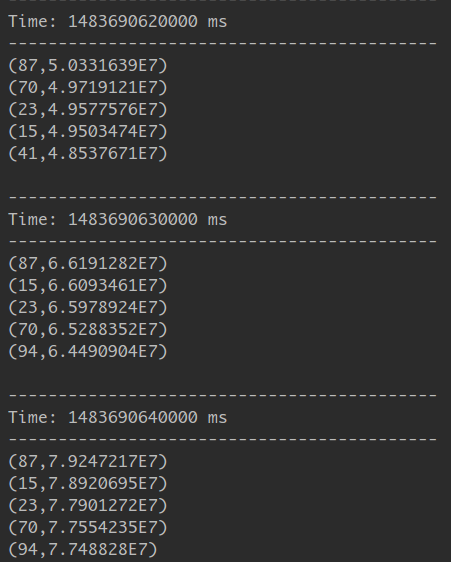
左邊ClientID,右邊排序的金額,達成。


